43: The DNA Code and its Codons
The above video is about my book Evo-illusion, now available at Amazon. The page begins below.
It’s far easier to fool someone than it is to convince them they have been fooled.
-Mark Twain
Below are keys for the Genetic Code, The Morse Code, and the Binary Code used for computers. The genetic code chart shows the key for the code RNA would take from DNA so it could go on to a ribosome, or cellular machine shop, and construct proteins like:
Hemoglobin – carries oxygen in your red blood cells
• Collagen – the most abundant protein in mammals. It makes up around a third of all proteins in the human body. Found in tendons, ligaments and skin, corneas, cartilage, bones, blood vessels, intervertebral discs
• Keratin – hair, nails
• Insulin – regulates blood sugar levels
• Histones – bind & organize DNA
• Antibodies – part of your immune system that recognizes foreign invaders such as bacteria
• Myosin – a protein involved in the contraction/extension of muscle fibers
• Growth factors – protein hormones that tell your body cells to grow and divide
• p53 – a tumor suppressor that can cause cancer if it mutates
• Integrin – attaches a cell to the tissue around it
An average protein is made up of over 500 amino acids attached in chains called polypeptides. Each amino acid requires three “code letters” so that the cell’s machinery can form a protein. The three code letters are called codons. They are actually not letters of course, but biochemicals called bases which make up the “rungs” of the coiled DNA ladder. Try to imagine how any of these three code keys could have been assembled one unit at a time. They would all be useless without the entire three base code key. Imagine a Morse Code with only one dash, or dot. Or a binary code with only an “0”; or “1”. Next try to imagine the genetic code with only one amino acid coded for, as evolution would require during the code’s formation. The key for the genetic code could not have been assembled one amino acid at a time over millions of years, just like the Morse code and Binary code keys would have been worthless one code unit at a time over many years. The genetic code alone makes a shambles of evolution, so any notions about its formation, slowly, one unit at a time, over millions of years is completely ignored by evolution. Why? Why isn’t the formation of the genetic code and its codons addressed by evolution scientists? The answer is obvious. The desire to believe, and not lose grants and jobs, overwhelms good science. In analyzing the validity of evolution, no other argument needs to be addressed. The DNA code, all by itself, eliminates evolution as the source of all living organisms. The true translation of the DNA code is: its time to reload. It’s time for science to move on, and look elsewhere. If there is no elsewhere, then it’s time for science to admit that fact, and just say “we don’t know”. Science has no idea why the universe is here instead of nothing, and no idea what life is or its origin. There is nothing wrong with the honesty needed to declare that humanity has no idea why living organisms are here, or what their source is.
There is a raging (and laughable) discussion in the evolution/ID debate about whether or not the DNA code is actually a code. Notice that every one of the twenty amino acids utilized by living nature (out of over 300 naturally existing amino acids) are identified by three bases, and only three, of the four bases, and only four, utilized for this coding. Evo-illusionsts would have a better argument, not a good one certainly, but a better one if each amino acid was identified by a different number of bases, and if there were a different selection of bases to choose from; but there are always three bases utilized out of four available for coding. But each amino acid needs and uses only three, much like the digital code has only two single-digit numbers, 1’s and 0’s, and the Morse code has only dots and dashes. Actually, the Morse code is more random-like than the DNA code, since it uses a differing number of dots and dashes, from one to five, to code for each letter of the alphabet. If a random number of random bases were used to code for a random number of amino acids in each species, it would sure look a lot better for evolution. But as always, nature is never good to this dubious science. Three bases of four are always selected to provide information which codes for the same twenty amino acids. Take a look at the charts below, and ask yourself which is the most random, and which is the most perfect and tidy. The top chart is the DNA code.


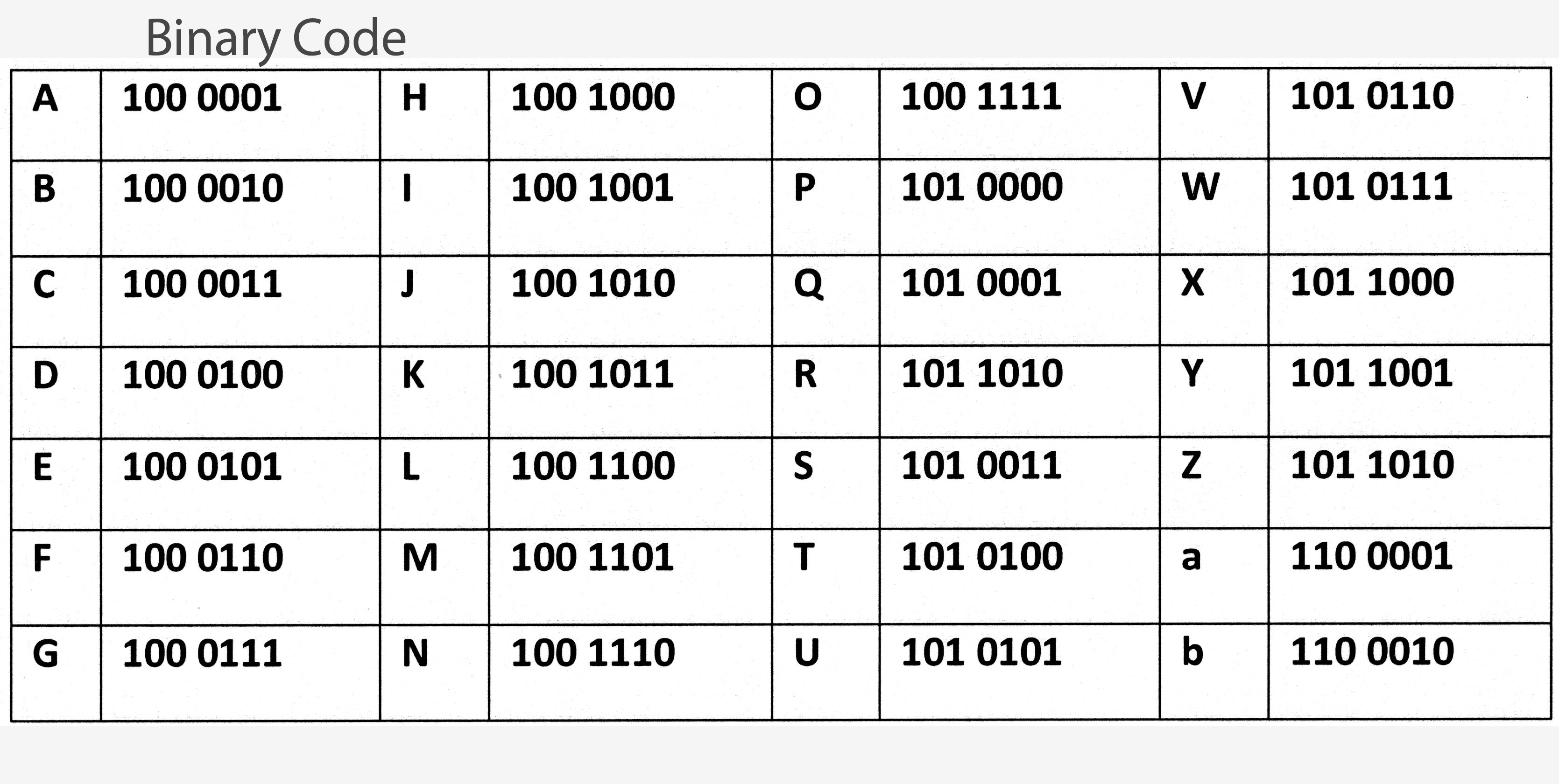

DNA is remarkable beyond imagination. To give you an idea of how amazing this genetically coded molecule is, let’s put into perspective the size of the cells that house our genetic code. An average human cell is so small that 10,000 of them would fit on the head of a pin. DNA is coiled and encapsulated inside the nucleus of each cell. DNA is made up of a “coiled ladder” type of molecule. The ladder rungs are composed of four different organic bases, two on each rung: adenine, thymine, guanine, and cytosine. Adenine always links to thymine, cytosine to guanine, and these links are called “base pairs”. The code is written AT, GC by biologists. Human DNA is composed of over three billion base pairs. The order of these links acts like a digital code that is the blueprint for cells to construct proteins which are the building blocks of life.
When the bases have certain types of sugars (ribose) and a phosphate group added, they then are molecules called nucleotides, which form the coiled side rails of the “ladder”. Each nucleotide side rail has it’s molecules in opposite order from the opposing side rail, making the molecules “anti-parallel”, which of course requires an incredible feat of assembly.
 To give you an idea of how long and thin our DNA is, five million strings of DNA would fit inside the eye of a sewing needle. For the fun of it, I added this astounding picture of an actual sewing needle with miniature sculptures in the eye made by a sculptor with an incredible talent! If the DNA from one single cell was unraveled, it would be six feet long! If DNA were 2″ wide, the molecule would be over 28,882.6 miles long! It would reach 3,000 miles more than all the way around the world. If DNA were movie film, and each individual “picture” represented a single rung, and twenty-four rungs went by the lens per second, it would take 1447 days, almost four years, to watch the entire film.
To give you an idea of how long and thin our DNA is, five million strings of DNA would fit inside the eye of a sewing needle. For the fun of it, I added this astounding picture of an actual sewing needle with miniature sculptures in the eye made by a sculptor with an incredible talent! If the DNA from one single cell was unraveled, it would be six feet long! If DNA were 2″ wide, the molecule would be over 28,882.6 miles long! It would reach 3,000 miles more than all the way around the world. If DNA were movie film, and each individual “picture” represented a single rung, and twenty-four rungs went by the lens per second, it would take 1447 days, almost four years, to watch the entire film.
The idea that this kind of molecule could self-assemble on the early earth sea floor, with the enormous tides, as the moon was 25,000 to 50,000 miles away, with the huge currents, with the seas being boiling hot, is just moronic at best. But this idea is pushed by evolution/abiogenesis scientists as “real science”. DNA is such a good example of why I say there is a lot more to the story of life’s origins than we humans can possibly understand.
What is really amazing about DNA is that it doesn’t key what each cell becomes, or start the differentiation of cells in the embryo. It doesn’t tell an undifferentiated cell in the embryo to become a lung cell, heart cell, blood cell, or any other type of cell. That job is done by an as yet unknown control center that must somehow exist in the cell’s cytoplasm. Cytoplasm is the semi-fluid substance of a cell that is present within the cellular membrane and surrounds the nuclear membrane. Cytoplasm is a thick and semi-transparent fluid made of 70% – 90% water. It’s usually colorless. Most of the cellular activities occurs in the cytoplasm. Cytoplasm is really all that is left that can house the control center of the cell. The discovery and understanding of the true control center is as yet beyond the ability of modern science. Since scientists have no idea what actually does the job of controlling cell function and type, it has been credited to DNA. The notion that DNA holds the plans for cell type is universally accepted in the world of biology. But DNA is not capable of doing that job. It’s only function, ability, and power is to hold code. It is not a conscious living breathing molecule. It has no ability to reach out and control the function and movement of all of the other molecules in a cell like a drone is controlled by a radio control box and human controller. Scientists pretty much understand and know the cell membrane (outer capsule), the nucleus, all of the organelles and most biochemicals inside of cells. The DNA in every cell’s nucleus holds all of the plans to make the cells 90,000 proteins, much like a computer’s hard drive holds all of the information for the computer. A control center in the cell’s cytoplasm must access the information in the DNA. The mysterious control center is ultimately is the decider of what the cell will become, and to where it will migrate so it is in proper position and can act as a building block for whatever organ the cell’s blueprint requires. It also controls the functions and goings-on inside of a cell.
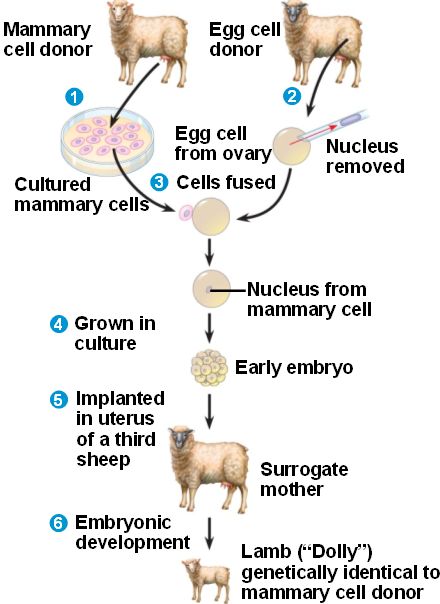 Proof that the control center of cells must be in the cytoplasm, and that it is as yet an unknown entity that determines the type of a particular cell was evidenced when Dolly, the sheep, was cloned. A sheep’s mammary cell was utilized for the cloning, which gave Dolly her name. She was named after Dolly Parton who is famous for her mammaries, of course. The nucleus of a mammary cell, which contained all of the DNA for a full sheep cell, was removed and placed inside of a sheep ovum that already had its nucleus removed. Of course, the ovum was a gamete containing only half of the DNA of a full sheep cell. Placing a whole nucleus with a full complement of DNA inside the DNA-less ovum “fooled” the ovum into “thinking” it had been impregnated by a sperm. The ovum began multiplying and differentiating into a normal sheep fetus. It formed an exact copy of the entire sheep that donated the mammary nucleus in the first place. If the DNA of the original mammary cell determined the phenotype of the newly growing embryonic cells, all of the newly forming cells of the embryo would become mammary cells and nothing else. But that was not the case. The embryo developed normally, and cell differentiation proceeded normally. Dolly, a fully living breathing healthy sheep formed, with all of its different organs and biological systems. Which means that the only place left in the cell that could be the control center which determines cell type and holds the blueprints for the entire sheep must exist somewhere in the cytoplasm. But where? Just when we think we have things down pat, fully understood, we don’t.
Proof that the control center of cells must be in the cytoplasm, and that it is as yet an unknown entity that determines the type of a particular cell was evidenced when Dolly, the sheep, was cloned. A sheep’s mammary cell was utilized for the cloning, which gave Dolly her name. She was named after Dolly Parton who is famous for her mammaries, of course. The nucleus of a mammary cell, which contained all of the DNA for a full sheep cell, was removed and placed inside of a sheep ovum that already had its nucleus removed. Of course, the ovum was a gamete containing only half of the DNA of a full sheep cell. Placing a whole nucleus with a full complement of DNA inside the DNA-less ovum “fooled” the ovum into “thinking” it had been impregnated by a sperm. The ovum began multiplying and differentiating into a normal sheep fetus. It formed an exact copy of the entire sheep that donated the mammary nucleus in the first place. If the DNA of the original mammary cell determined the phenotype of the newly growing embryonic cells, all of the newly forming cells of the embryo would become mammary cells and nothing else. But that was not the case. The embryo developed normally, and cell differentiation proceeded normally. Dolly, a fully living breathing healthy sheep formed, with all of its different organs and biological systems. Which means that the only place left in the cell that could be the control center which determines cell type and holds the blueprints for the entire sheep must exist somewhere in the cytoplasm. But where? Just when we think we have things down pat, fully understood, we don’t.
According to The Guardian.com:
The living cell is best thought of as a supercomputer – an information processing and replicating system of astonishing complexity. DNA is not a special life-giving molecule, but a genetic databank that transmits its information using a mathematical code. Most of the workings of the cell are best described, not in terms of material stuff – hardware – but as information, or software. Trying to make life by mixing chemicals in a test tube is like soldering switches and wires in an attempt to produce Windows 98. It won’t work because it addresses the problem at the wrong conceptual level. How did nature fabricate the world’s first digital information processor – the original living cell – from the blind chaos of blundering molecules? How did molecular hardware get to write its own software? The answer must wait until we understand the nature of information and the principles that govern its dynamics and complexity.
Another major setback occurred to evo-illusion in 2006 when the Human Genome Project was completed. It was always thought that one single gene coded for one single protein. There are 90,000 human proteins, so it was expected that human genome mapping would show several hundred thousand genes, enough to code for all of the 90,000 human proteins, plus there should be plenty left over to code for cell type, body type, and all human characteristics. But shock of shocks, the Human Genome Project counted only 20,000 genes! So now what? What was science to do? We were short 70,000 genes needed to make only proteins! There weren’t nearly enough to code only for human proteins! There were certainly none that would code for cell type, body type, and all human characteristics. A new theory of protein assembly had to be made. Instead of one gene coding for one protein, segments of different genes would code for one protein. They would then be spliced together to form an mRNA molecule that would code for a single protein. In other words, building the code for one protein would require mRNA to take a bit of code from multiple genes. Can you imagine the increased complexity that exploded on the scene when the Genome Project was completed? mRNA had to swim around to multiple locations on the DNA molecule to make up its code for one protein. Each location on the DNA molecule had to be opened, unwound, and unzipped to make itself ready to donate a portion of code that makes up a single mRNA molecule. In doing so, it would pick up unneeded coding, called introns. These have to go through another fantastic series of steps be edited out before a properly coded mRNA molecule can result. The complexity in forming a single protein, while it was infinitely complex before 2006, became exponentially more complex, if that’s possible. Of course, this information should have killed the notion that randomly selected mutations formed all of living nature. But the effect information has on the science of origins has been basically swept under the rug and ignored by evo-illusion scientists. If you would like to see how gene splicing works, here is a short video on the subject:
If you are not up on how DNA is utilized to make proteins, this is an excellent basic video on the subject. Of course, it’s a far more complex process than portrayed here. Interestingly, in this video, the mRNA molecule is formed whole, without the editing of splicing shown in the above video. It was either made before 2006, or the makers of the video eliminated splicing for simplicity:
(1) The Genius Within, pp. 116-120, Dr. Frank Vertosick Jr. Harcourt Inc.2002
(2) Mitchel, Campbell Reece. Biology Concept and Connections. California, 1997. “At actual size, a human cell’s DNA totals about 3 meters in length.” 3.0 m
(3) McGraw Hill Encyclopedia of Science and Technology. New York: McGraw Hill, 1997. “If stretched out, would form very thin thread, about 6 feet (2 meters) long.” 2.0 m
(4) Matthews, Harry R. DNA Structure Prerequisite Information. 1997. “The length is (length of 1 bp)(number of bp per cell) which is (0.34 nm)(6 × 109)” 2.0 m
(5) Leltninger, Albert L. Biochemistry. New York: Worth, 1975. “Chromosome 13 contains a DNA molecule about 3.2 cm long.” 1.5 m
“Cell.”
(6) The World Book Encyclopedia. Chicago: Field Enterprises, 1996. “On the average, a single human chromosome consists of DNA molecule that is about 2 inches long.” 2.3 m
(3) http://www.theguardian.com/education/2002/dec/11/highereducation.uk
Paul Davies, The Guardian, Wednesday 11 December 2002 04.46 EST

{kind=link}
Amino Acids Chart | qmsdnug.org said,
September 9, 2019 at 4:53 am
[…] Download Image More @ evoillusion.org […]